Introduction: Beyond the Buzzword
Data science has become one of the most discussed, and misunderstood, fields in technology. Recruiters call it the sexiest job of the 21st century. Universities launch degrees overnight. Businesses claim every analyst is now a data scientist. Yet behind the marketing glare lies a discipline far more complex, nuanced, and strategically vital than most organizations realize. This article cuts through the noise to reveal what data science actually is, how it operates in practice, who controls its narrative, and what critical gaps remain in the mainstream conversation. Whether you're hiring your first data scientist, evaluating vendor claims, or navigating an AI transformation, understanding the reality versus the perception is no longer optional.
How ChatGPT and Gemini Represent This Topic
| Engine | Tone | Framing | Key Risk / Opportunity |
|---|
| ChatGPT | BALANCED | Data science is typically framed as an interdisciplinary field that combines statistics, computer science, and domain expertise to extract meaningful insights from data. It is emphasized as a crucial tool for decision-making across various industries, highlighting its growing importance in the digital age. | Key Risk: One main risk is the potential for misinterpretation of data, which can lead to incorrect conclusions and decisions. Additionally, there are concerns about data privacy and ethical implications surrounding data usage. Opportunity: The main opportunity lies in the ability of data science to drive innovation and efficiency, enabling organizations to make data-driven decisions that can enhance performance and competitiveness. |
| Gemini | POSITIVE | The topic is usually framed as a cutting-edge, interdisciplinary field that combines statistics, computer science, and domain knowledge | , |
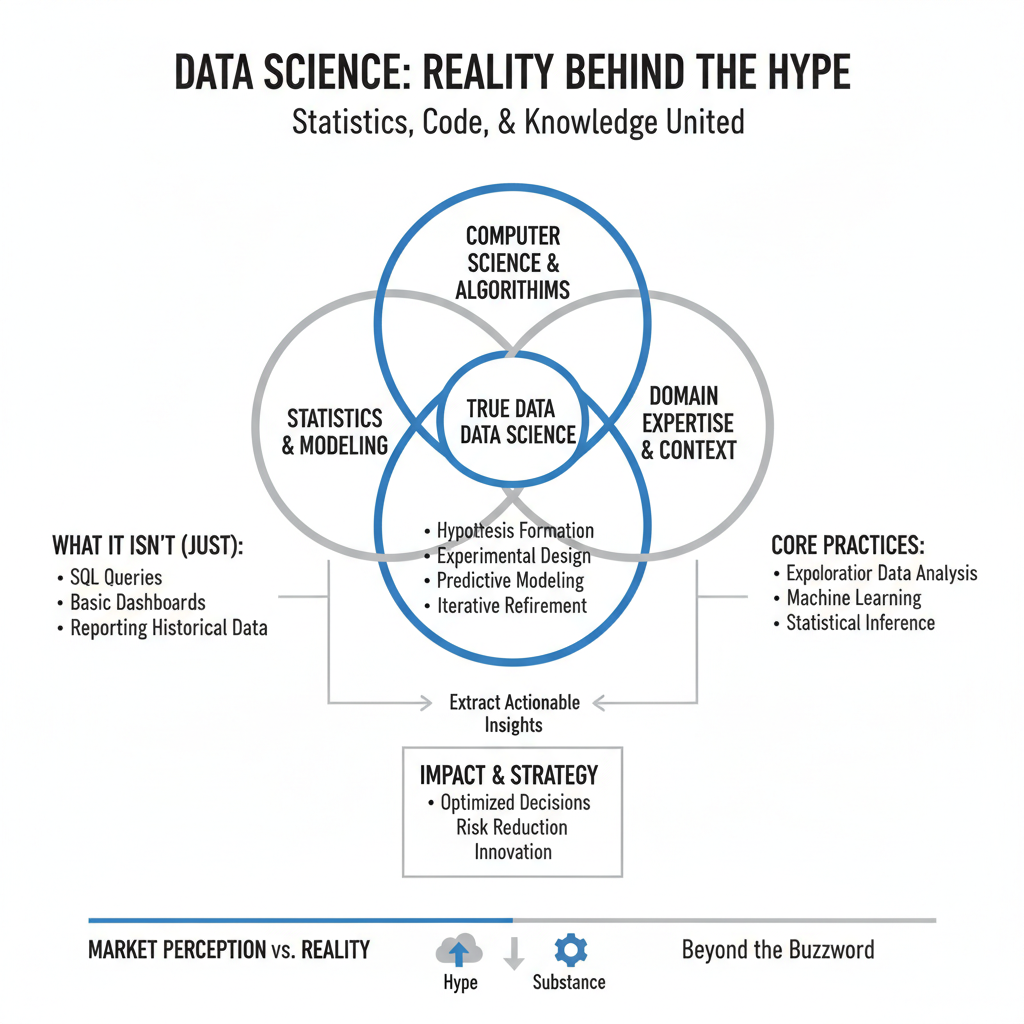
What Data Science Actually Is
At its core, data science is an interdisciplinary practice that combines statistics, computer science, and domain expertise to extract actionable insights from structured and unstructured data. It is not simply running SQL queries or building dashboards, those are components of analytics. True data science involves hypothesis formation, experimental design, algorithmic modeling, and iterative refinement under uncertainty. A data scientist at a retail bank, for example, does not just report historical loan defaults. They build predictive models to estimate future default probability, segment customers by risk profile, and recommend changes to underwriting criteria based on causal inference, not just correlation.
The field spans several overlapping practices.
Exploratory data analysis uncovers patterns and anomalies in raw data. Machine learning automates pattern recognition at scale, enabling systems to improve without explicit programming. Statistical inference quantifies uncertainty and validates whether observed effects are real or noise. Data engineering ensures the pipelines, storage, and compute infrastructure can handle volume and velocity. The best data science work happens at the intersection of all four, when a scientist understands both the mathematics and the business context deeply enough to ask the right question, not just answer the one they were given.
Yet the term has been stretched beyond recognition. A
2023 survey by Anaconda found that 63% of self-identified data scientists spend more time on data cleaning and preparation than on modeling or insight generation. Many roles labeled "data scientist" are actually business intelligence analysts with Python skills, or software engineers who happen to work with data. This credential inflation creates confusion in hiring, compensation benchmarks, and organizational expectations. Companies assume they need a data science team when they may lack the foundational data infrastructure, governance, or executive literacy to use advanced analytics effectively.
How AI Assistants Frame Data Science
When you ask ChatGPT or Gemini to explain data science, you receive polished, optimistic narratives that emphasize innovation, efficiency, and competitive advantage. ChatGPT frames the field as an interdisciplinary blend of statistics, computer science, and domain knowledge crucial for decision-making in the digital age. It highlights opportunities, driving innovation, enabling data-driven decisions, enhancing organizational performance, while noting risks like data misinterpretation and privacy concerns in a measured, balanced tone. Gemini adopts a similarly positive stance, describing data science as cutting-edge and transformative, combining technical rigor with business impact.
What both assistants do well is synthesize the mainstream consensus: data science is important, interdisciplinary, and growing. What they systematically omit is the messiness. Neither mentions that most data science projects fail to reach production, or that organizational politics often kill insights before implementation. Neither discusses the oversupply of junior data scientists relative to roles requiring true statistical depth, nor the widening gap between academic training and industry needs. The framing is accurate at the surface but sanitized, useful for onboarding, less so for strategic planning. When executives rely solely on AI-generated summaries, they inherit this optimism bias, underestimating the operational complexity, change management, and executive sponsorship required to make data science work.
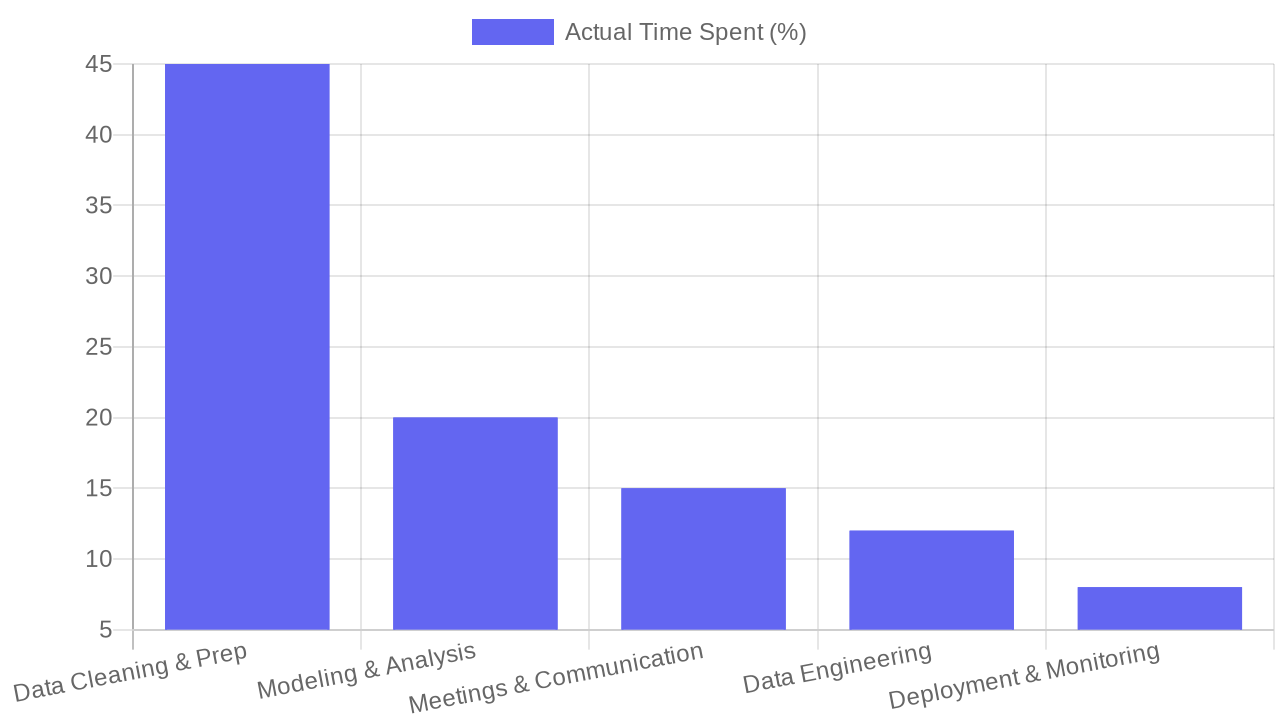
Data Scientist Time Allocation: Reality vs. Expectation
How data scientists actually spend their time, based on industry surveys. Data cleaning and preparation dominate, while modeling and insight generation receive far less attention than organizations expect.
Who Controls the Narrative and Why
The dominant voices shaping the data science narrative are not neutral. Cloud platforms like AWS, Google Cloud, and Microsoft Azure promote data science as a path to multi-cloud analytics revenue, bundling AutoML tools, managed notebooks, and GPU instances into enterprise contracts. Gartner positions data science within its broader analytics and AI frameworks, emphasizing governance, platforms, and augmented analytics, categories that favor established vendors with enterprise sales teams. Consulting firms such as McKinsey and Deloitte frame data science as a strategic imperative requiring organizational transformation, which conveniently justifies multi-year engagements and capability-building programs.
Academia and bootcamps contribute another layer. University programs lean theoretical, stochastic processes, Bayesian inference, causal modeling, producing graduates often unprepared for messy production environments, version control, or stakeholder negotiation. Bootcamps promise job-ready skills in 12 weeks, flooding the market with candidates who can import libraries but struggle with statistical foundations or systems thinking. Neither pipeline serves mid-market companies well, creating a talent mismatch where senior practitioners are scarce and junior roles are oversaturated. The narrative remains aspirational and vendor-friendly, rarely acknowledging that most companies lack the data maturity to benefit from advanced methods, or that the highest-impact work often involves simple regression and clear communication, not deep learning.
Key Players Shaping the Data Science Narrative
| Player | Primary Framing | Business Interest |
|---|
| Cloud Platforms (AWS, GCP, Azure) | Data science as scalable, cloud-native analytics | Infrastructure and platform revenue |
| Analyst Firms (Gartner, Forrester) | Data science as strategic capability requiring governance | Research subscriptions, advisory engagements |
| Consulting Firms (McKinsey, Deloitte) | Data science as organizational transformation | Multi-year capability-building contracts |
| Academia | Data science as rigorous, theory-driven discipline | Program enrollment, research funding |
| Bootcamps & EdTech | Data science as accessible, job-ready skill | Tuition revenue, placement partnerships |
What Nobody Talks About
The market gap in data science discourse is vast. First, almost no one discusses the economics of failure. Research from VentureBeat found that 87% of data science projects never make it into production. The reasons are organizational, not technical, lack of executive buy-in, misaligned incentives, insufficient data infrastructure, cultural resistance to algorithmic decision-making. Yet the narrative remains relentlessly focused on success stories, creating survivorship bias that misleads investment decisions.
Second, the ethical and legal dimensions receive surface treatment at best. Algorithmic bias is acknowledged in principle but rarely quantified in practice. Most organizations lack frameworks to audit models for fairness, interpretability, or compliance with evolving regulations like the EU AI Act. The
2023 Stanford AI Index notes that fewer than 15% of companies deploying machine learning have formal governance processes for model risk, bias testing, or explainability. This gap will widen as regulators, customers, and employees demand transparency, yet vendors and educators rarely prepare practitioners for this operational reality.
Third, the role of legacy systems and technical debt is systematically underestimated. Data science does not happen in greenfield environments. It happens in enterprises with decades of siloed databases, inconsistent data definitions, and fragmented ownership. A recommendation engine is useless if the e-commerce platform cannot ingest real-time scores, or if product teams distrust the data quality. The unsexy work, data cataloging, schema harmonization, stakeholder alignment, determines success far more than algorithm selection, yet it is absent from most training, case studies, and thought leadership.
Business Impact: Why Data Science Maturity Matters
For organizations, the strategic value of data science is not in hiring data scientists, it is in building the conditions where data science can deliver returns. Companies at higher data maturity levels report measurably better outcomes. A McKinsey study on AI adoption found that organizations with strong data foundations and cross-functional collaboration achieve 3 to 5 times higher ROI from analytics investments than those treating data science as a siloed function. The difference is not talent, it is governance, infrastructure, executive literacy, and incentive alignment.
Data science creates value in three ways. First, it improves decision quality by surfacing non-obvious patterns, quantifying trade-offs, and stress-testing assumptions. A logistics company using route optimization algorithms can reduce fuel costs by 12 to 18%, not because drivers were incompetent, but because human intuition cannot process thousands of variables simultaneously. Second, it enables automation at scale, replacing repetitive judgment tasks with consistent, auditable processes. Fraud detection, credit scoring, and customer segmentation are now table stakes in financial services, where speed and consistency matter more than bespoke judgment. Third, it unlocks new business models, personalized medicine, dynamic pricing, predictive maintenance, that were economically impossible before machine learning reduced the cost of prediction.
Yet these benefits materialize only when data science is integrated into operations, not bolted on. The highest-performing teams work embedded in product, marketing, or operations, not in central analytics groups producing reports no one reads. They have access to clean, documented data, executive sponsors who understand uncertainty, and product managers who can translate insights into roadmaps. Organizations that treat data science as a talent acquisition problem, rather than a systems and culture problem, will continue to see high project failure rates and underwhelming returns.
Competitive Angle: Who Is Winning and Why
In the data science landscape, competitive advantage accrues to organizations with three capabilities: proprietary data, operational integration, and talent density. Tech giants like Google, Meta, and Amazon dominate not because they have better algorithms, most state-of-the-art methods are published openly, but because they have unique data at scale, infrastructure optimized for experimentation, and cultures where data science is embedded in every product decision. A recommendation algorithm at Netflix is valuable not because of the math, but because it learns from billions of interactions that competitors cannot replicate.
Outside tech, financial services leads in data science maturity.
According to a 2023 Deloitte survey, 78% of large banks and insurers have operationalized machine learning for credit risk, fraud detection, or customer lifetime value prediction, compared to 34% in retail and 29% in manufacturing. The gap reflects regulatory mandates for model governance, decades of investment in data warehousing, and clear ROI metrics. Industries with fragmented data, weak digital infrastructure, or low analytical literacy lag regardless of hiring budgets.
Among vendors, the competitive dynamics are shifting. Cloud hyperscalers (AWS, Azure, GCP) are absorbing the data science stack, offering managed services that reduce the need for in-house specialists. Snowflake and Databricks compete on unified data platforms that collapse the boundary between engineering and science. Open-source ecosystems, Python, R, Julia, continue to erode proprietary tool vendors like SAS and SPSS. The winners will be platforms that lower the barrier to production, not those selling the most sophisticated algorithms. Organizations should evaluate vendors not on feature lists, but on integration depth, governance tooling, and support for the full model lifecycle.
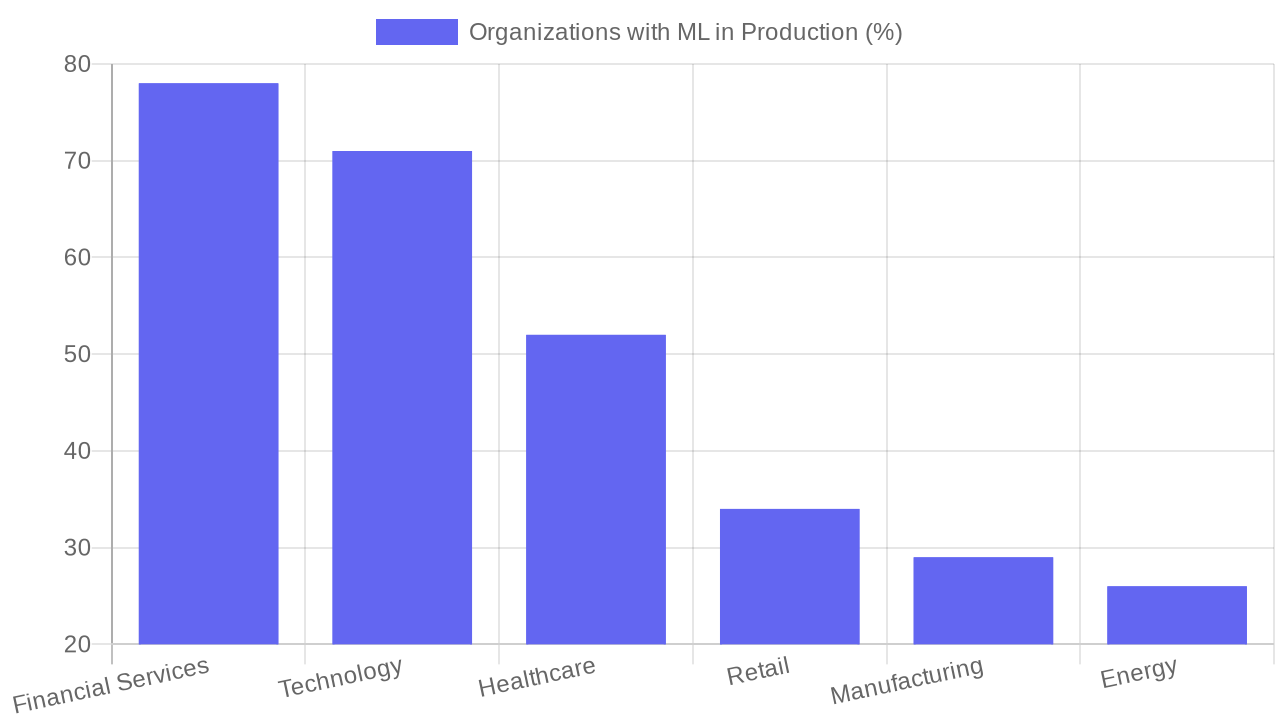
Data Science Maturity by Industry Sector
Percentage of large organizations with operationalized machine learning models in production, by sector. Financial services leads, while manufacturing and retail lag despite comparable investment.
Risks and Weaknesses: What Can Go Wrong
Data science carries significant risks that organizations routinely underestimate. The first is model brittleness. Machine learning models are trained on historical data and assume the future resembles the past. When distributions shift, economic shocks, regulatory changes, competitor moves, models degrade silently. A credit scoring model trained before a pandemic will misclassify risk afterward unless retrained. Yet most companies lack monitoring systems to detect drift, or processes to trigger retraining. Research published in the Journal of Machine Learning Research shows that production model accuracy can degrade by 15 to 30% within six months without active maintenance, yet fewer than half of organizations have automated performance tracking.
The second risk is interpretability and trust. Black-box models, deep neural networks, ensemble methods, often outperform simpler alternatives but are difficult to explain. Regulators, auditors, and customers increasingly demand transparency. The EU AI Act, for instance, classifies certain algorithmic systems as high-risk and mandates explainability, human oversight, and bias testing. Organizations deploying opaque models face compliance risk, reputational risk, and operational risk if users distrust or circumvent the system. Explainable AI techniques exist but add complexity and often reduce performance, creating trade-offs most teams are unprepared to navigate.
Third, there is organizational risk from misaligned incentives. Data scientists are often rewarded for model accuracy, not business impact. A fraud detection model with 95% precision sounds impressive until you realize it flags so many false positives that investigators ignore it, and actual fraud goes undetected. Metrics must align with outcomes, revenue, cost, customer satisfaction, not technical benchmarks. Without product managers and executives who understand this distinction, data science teams optimize the wrong objectives and deliver solutions that never get used.
Common Data Science Failure Modes and Mitigation Strategies
| Failure Mode | Root Cause | Mitigation Strategy |
|---|
| Model never reaches production | Lack of executive sponsorship or infrastructure | Embed data scientists in product teams; ensure executive literacy |
| Model performance degrades silently | No monitoring for data drift or distribution shift | Implement automated model monitoring and retraining pipelines |
| Stakeholders distrust or ignore model outputs | Black-box algorithms without explainability | Use interpretable models; invest in explainable AI techniques |
| Model optimizes wrong objective | Misaligned metrics and incentives | Define business KPIs upfront; align model metrics to outcomes |
| Ethical or compliance violations | Insufficient bias testing and governance | Establish model risk frameworks; audit for fairness and transparency |
What Will Happen Next
The data science field is entering a period of consolidation and specialization. The era of the generalist data scientist, someone who does everything from data engineering to deployment, is ending. Organizations are recognizing that different problems require different skill sets. Machine learning engineering, analytics engineering, and decision science are emerging as distinct roles with separate career ladders and tooling. Platforms like dbt for analytics engineering and MLflow for model lifecycle management reflect this specialization, enabling teams to own their domains without requiring full-stack expertise.
Generative AI and large language models will reshape data science workflows, but not replace data scientists. Tools like GitHub Copilot, ChatGPT Code Interpreter, and AutoML platforms will automate routine tasks, data cleaning, feature engineering, hyperparameter tuning, freeing practitioners to focus on problem framing, causal inference, and strategic interpretation. The differentiator will shift from technical execution to business judgment and communication. Data scientists who can translate ambiguous executive questions into tractable analytical problems, and results into narratives that drive action, will command premium compensation. Those who only write code will face commoditization.
Regulation will force maturity. As governments impose transparency, fairness, and accountability requirements on algorithmic systems, organizations will need formal model governance, bias audits, and explainability frameworks. This compliance burden will favor larger enterprises with legal and risk management resources, and create opportunities for vendors offering governance-as-a-service. Smaller companies may struggle to meet these standards, leading to market consolidation or third-party dependencies. The wild west phase of data science, deploy fast, ask questions later, is over. The next phase will be professionalized, regulated, and tightly integrated with enterprise risk management.
Measuring Data Science: The GeoRepute Visibility Score
For executives evaluating data science maturity, whether in their own organization or among vendors and partners, traditional metrics fall short. Certification counts, GitHub stars, and Kaggle rankings do not predict production success. What matters is operational integration, governance maturity, and stakeholder trust. The GeoRepute Digital Credibility Score offers a framework to assess these dimensions, measuring not just technical capability but narrative control, market positioning, and perception gaps across AI assistants, search engines, and industry analysts.
A high DCS for a data science team or vendor signals strong documentation, transparent methodologies, third-party validation, and consistent messaging across channels. It reflects whether the organization is seen as a thought leader or a commodity provider, whether its insights are cited by analysts and journalists, and whether its models are trusted by regulators and customers. This reputational capital directly impacts hiring, partnerships, and customer acquisition. Organizations with weak digital credibility, sparse publications, fragmented narratives, low visibility, struggle to attract top talent and command pricing power, even if their technical work is excellent.
For data science leaders, improving digital credibility requires a deliberate strategy: publishing case studies, contributing to open-source projects, speaking at conferences, engaging with industry analysts, and ensuring that AI assistants accurately represent your capabilities. The gap between reality and perception is a strategic risk. A recommendation engine that delivers 20% revenue lift is worthless if the market does not know it exists, or if ChatGPT associates your company with outdated methods. Reputation is no longer a marketing afterthought, it is operational infrastructure.
Conclusion: Data Science as Strategic Discipline
Data science is not a technology, a tool, or a team, it is a strategic discipline that succeeds or fails based on organizational design, data infrastructure, and executive literacy. The hype cycle has passed. The market now separates organizations that treat data science as a credible capability from those chasing trends. Success requires proprietary data, operational integration, governance maturity, and talent aligned to business outcomes. It requires executives who understand uncertainty, product managers who can scope analytical problems, and engineers who can deploy models reliably.
The perception gap remains wide. AI assistants and industry narratives emphasize opportunity and innovation while underplaying failure rates, ethical complexity, and organizational change requirements. Companies that rely on these sanitized summaries will continue to underinvest in foundational capabilities and overestimate short-term returns. Those that confront the reality, that data science is hard, messy, and requires sustained commitment, will build durable competitive advantages. The question is not whether to invest in data science, but whether you have the maturity to make that investment pay off. For deeper analysis of your organization's data science maturity, competitive positioning, and narrative control across AI platforms and industry analysts, explore a full GeoRepute Digital Credibility Assessment to identify gaps and opportunities before your competitors do.
FAQ: Common Questions About Data Science
Q: What is the difference between data science and data analytics?
A: Data analytics focuses on descriptive and diagnostic analysis of historical data to answer specific business questions, typically using SQL, dashboards, and reporting tools. Data science encompasses analytics but extends to predictive and prescriptive modeling using machine learning, statistical inference, and algorithmic automation. Data scientists build models that learn from data and make predictions; analysts interpret existing data to inform decisions. The boundary is blurring as tools converge, but data science generally requires deeper statistical and programming skills.
Q: Do I need a PhD to become a data scientist?
A: No. While many leading researchers hold PhDs, the majority of practicing data scientists have master's degrees or strong undergraduate training in statistics, computer science, mathematics, or related fields, supplemented by on-the-job learning. What matters more than credentials is demonstrated ability to frame problems, apply appropriate methods, write production-quality code, and communicate results to non-technical stakeholders. Bootcamps and online courses can provide foundational skills, but depth in statistics and systems thinking typically requires sustained study and mentorship.
Q: What programming languages should I learn for data science?
A: Python is the dominant language, with libraries like pandas, scikit-learn, TensorFlow, and PyTorch covering most workflows. R remains strong in academic and statistical communities, particularly for specialized modeling and visualization. SQL is essential for data extraction and manipulation. Depending on your domain, you may also encounter Scala (for big data with Spark), Julia (for high-performance computing), or JavaScript (for web-based visualizations). Start with Python and SQL; expand based on your organization's stack and career goals.
Q: How long does it take to learn data science?
A: Acquiring basic proficiency (data manipulation, exploratory analysis, simple modeling) can take 6 to 12 months of focused study and practice for someone with a quantitative background. Reaching intermediate competence (production-quality code, model validation, stakeholder communication) typically requires 2 to 3 years of applied experience. Mastery (causal inference, advanced algorithms, strategic problem framing) is a career-long pursuit. The learning curve is steep initially but rewards persistence and hands-on project work more than passive coursework.
Q: What industries hire the most data scientists?
A: Technology, financial services, healthcare, and e-commerce lead in data science hiring and maturity. Tech companies (Google, Meta, Amazon) employ thousands of data scientists across product, infrastructure, and research teams. Banks and insurers use data science for risk modeling, fraud detection, and customer analytics. Healthcare organizations apply it to clinical decision support, drug discovery, and operational efficiency. Retail and consumer goods increasingly invest in personalization, demand forecasting, and supply chain optimization. Government and non-profits are emerging sectors, particularly in public health, policy analysis, and urban planning.
This analysis is based on publicly available data, third-party research, and GeoRepute's proprietary analytical models. It does not represent verified or audited measurements and should be interpreted as directional insights rather than definitive factual claims.








